
Drafting & Regulatory Summarization
The current strength of LLMs lies in "Architectural Knowledge Management" (AKM). They are highly effective at generating Architecture Decision Records (ADRs), documenting the context and consequences of design choices with accuracy comparable to human drafts. [1]
Furthermore, LLMs excel at ingesting complex regulatory texts—such as zoning ordinances and the IBC—answering queries like "What is the maximum height in Zone R-5?" significantly faster than manual search. [2]
Lastly, LLMs are generally a good reserach method, for example the 'deep research' of gemini. They can proide an in-depth referenced report about any topic like; location study, new technologies and legal advice.
Multi-Agent Reasoning Systems
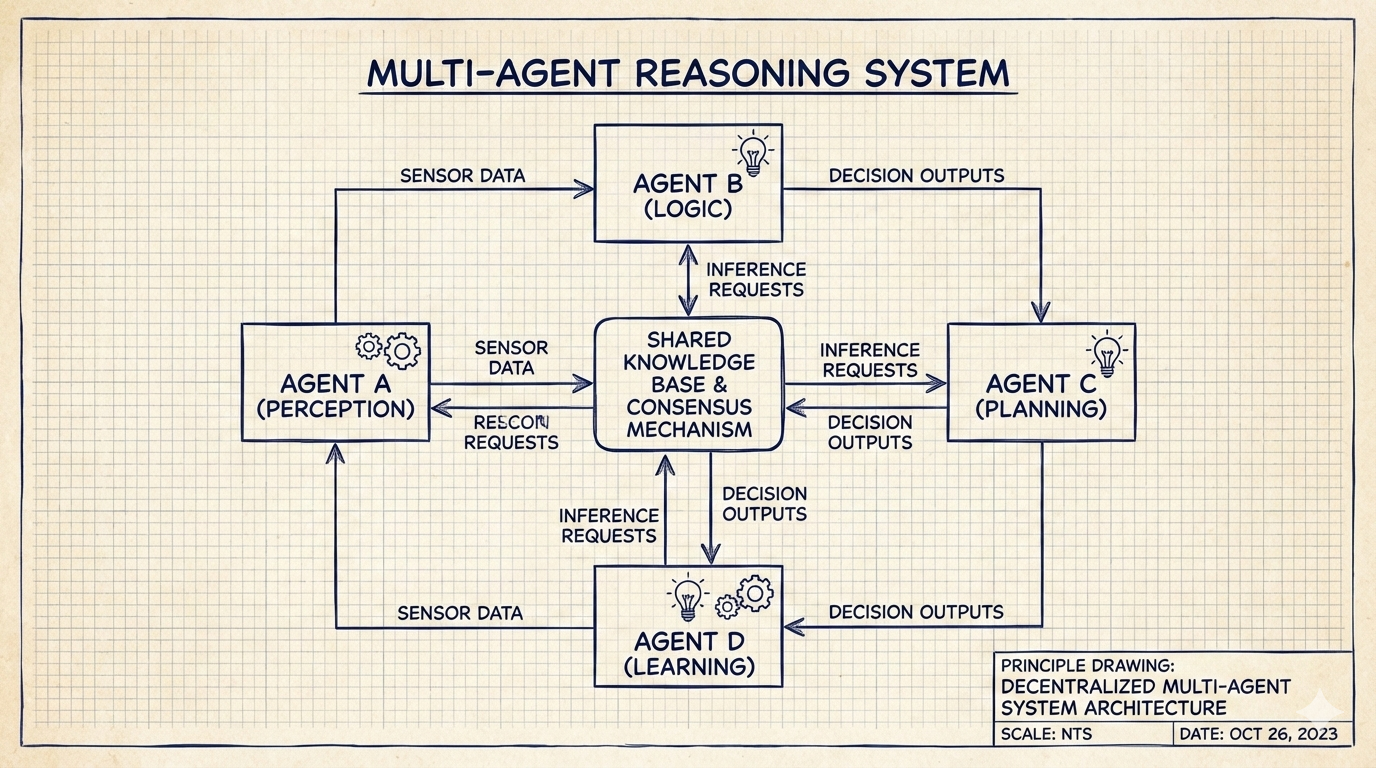
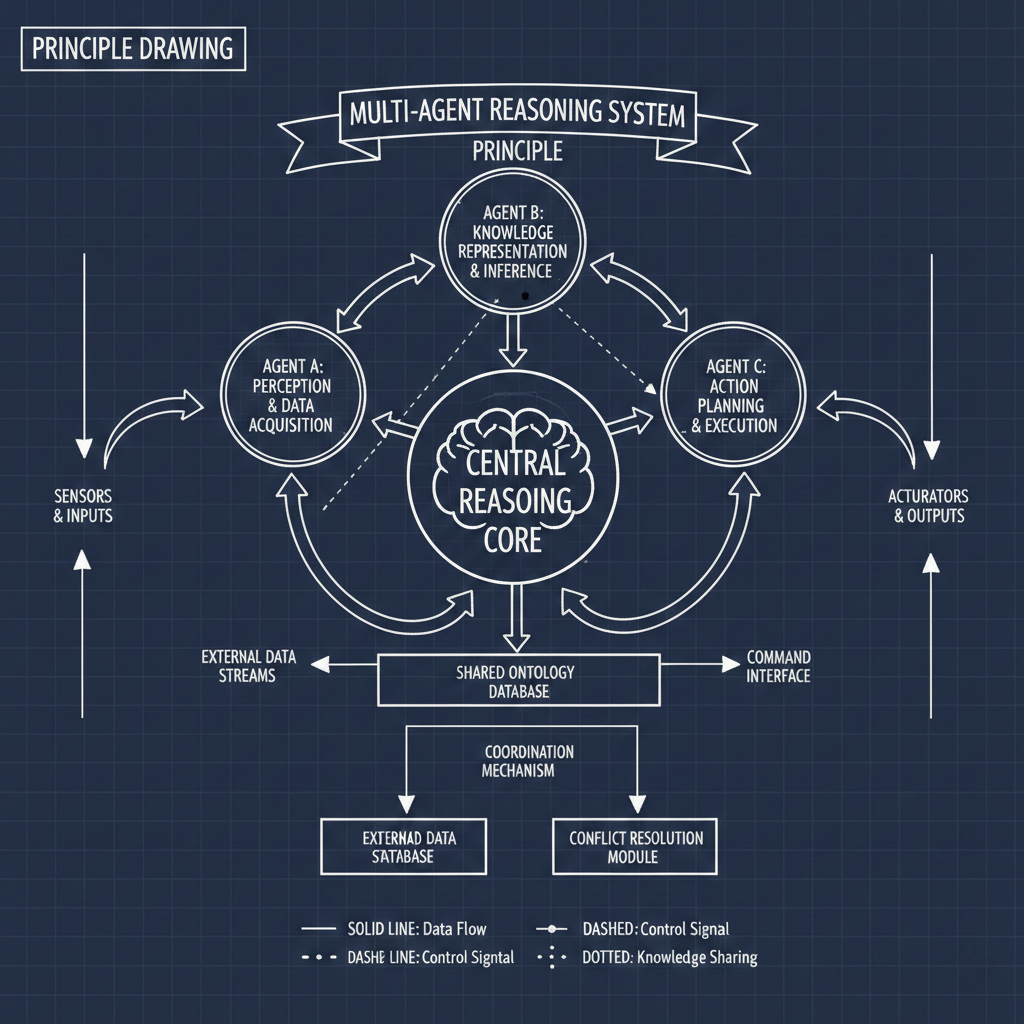
Text based AI's are moving beyond the "chatbot" toward Multi-Agent Systems (MAS) where specialized agents collaborate. In a compliance workflow, a "Planner" agent might interpret regulation while a "Code Expert" retrieves BIM data to execute logic checks. [3]
These systems allow for parallel execution—drafting narratives and verifying citations simultaneously—significantly speeding up complex reasoning tasks. [4]
Autonomous Law & Semantic Geometry
Theoretically, LLM-based systems could handle the contractual phase of architecture, with autonomous "Legal Agents" negotiating Owner-Architect agreements in real-time. [4]
Additionally, Multimodal LLMs suggest a future where models "read" floor plans as fluently as text, allowing architects to discuss spatial qualities (e.g., "too enclosed") which the model translates into geometric modifications. [5]

The Hallucination Hazard
The "Hallucination" problem is the Achilles' heel of professional practice. LLMs frequently invent fictitious court cases or building codes; relying on them can lead to findings of gross negligence. [6]
They also suffer from "Data Drift": confidentially providing outdated information because they do not "know" about code updates that occurred after their training cutoff. [7]
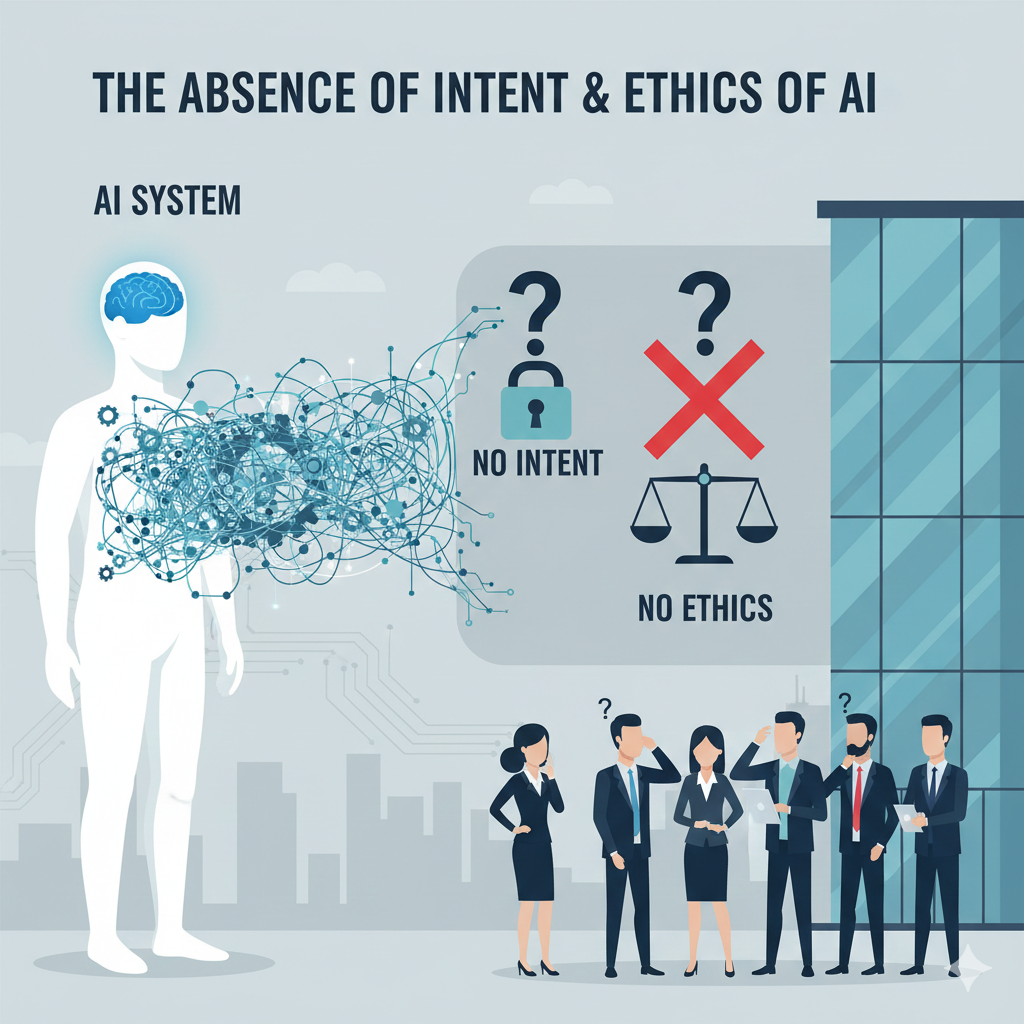
Absence of Intent & Ethics
An AI cannot seal a drawing. Legal liability relies on the "duty of care," and courts have ruled that responsibility (as of yet) cannot be transferred to a machine. [6]
Furthermore, AI cannot navigate ethical tensions—such as gentrification vs. development. These are value judgments requiring a human conscience, not optimization problems. [8]